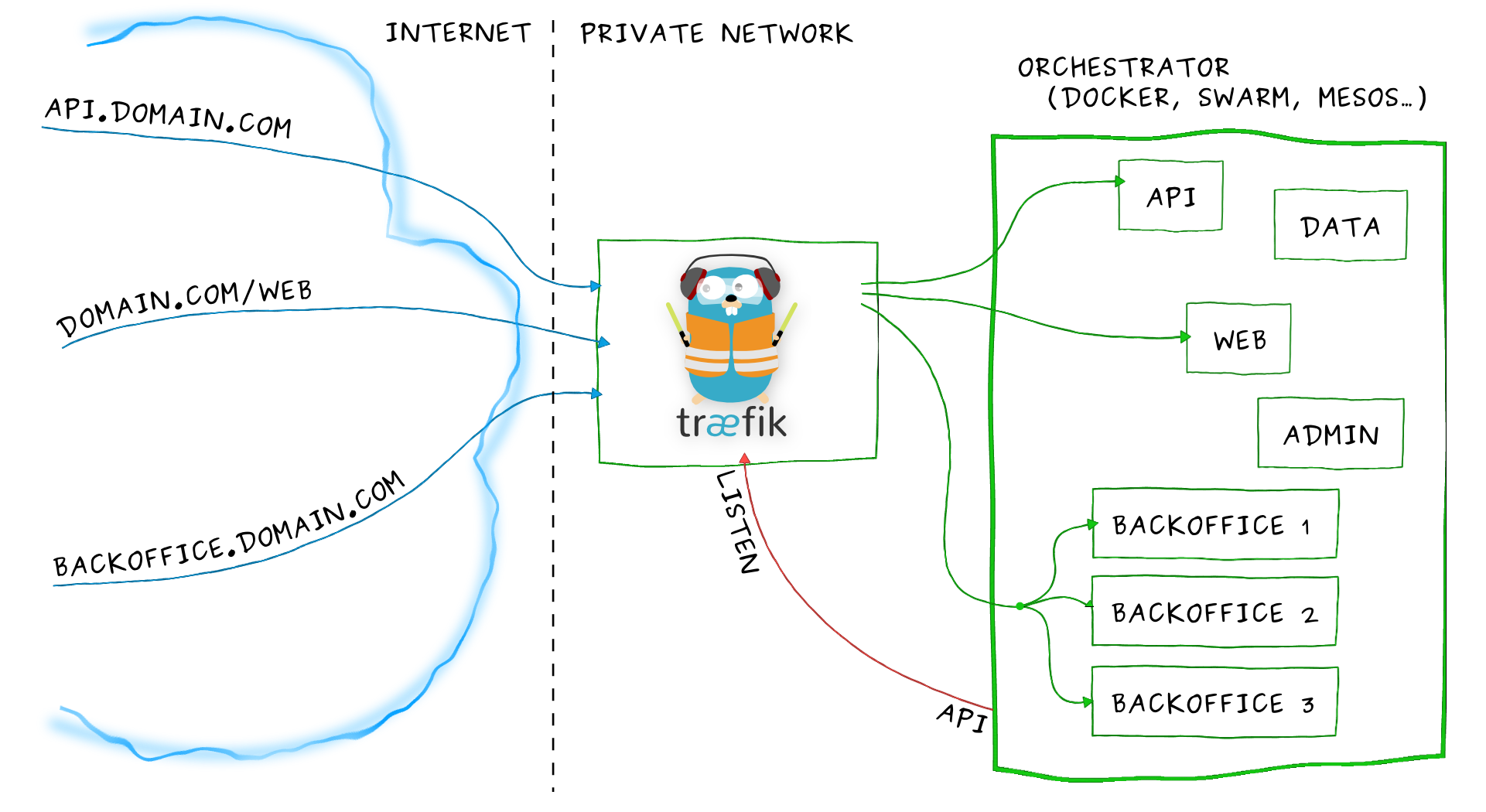
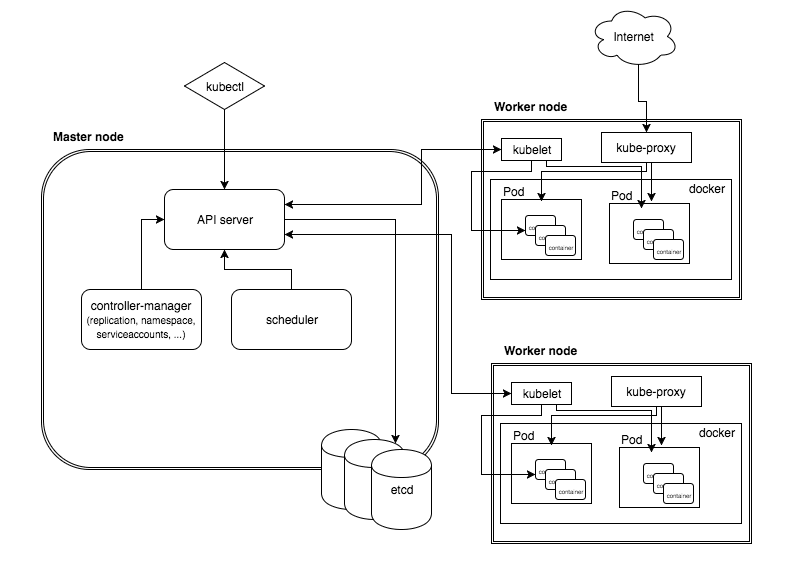
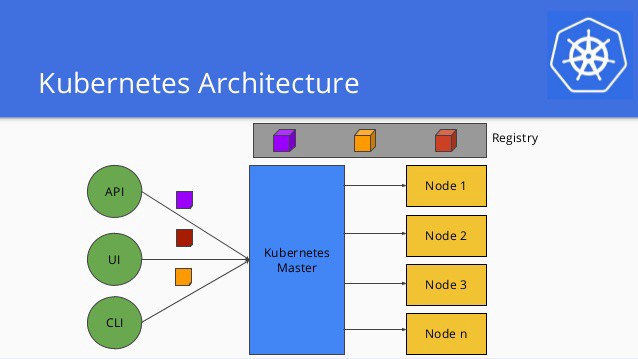
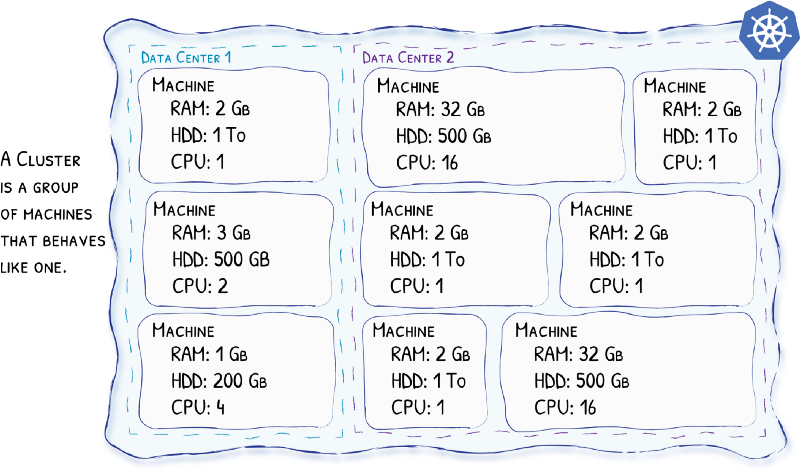
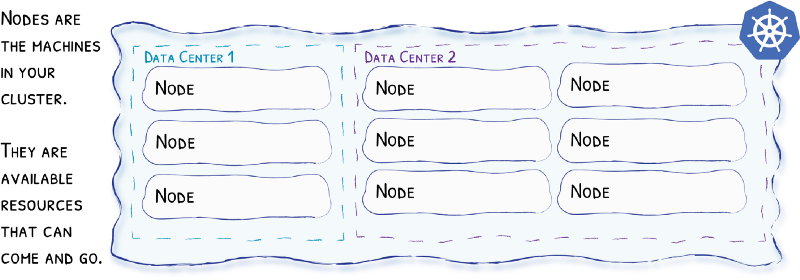
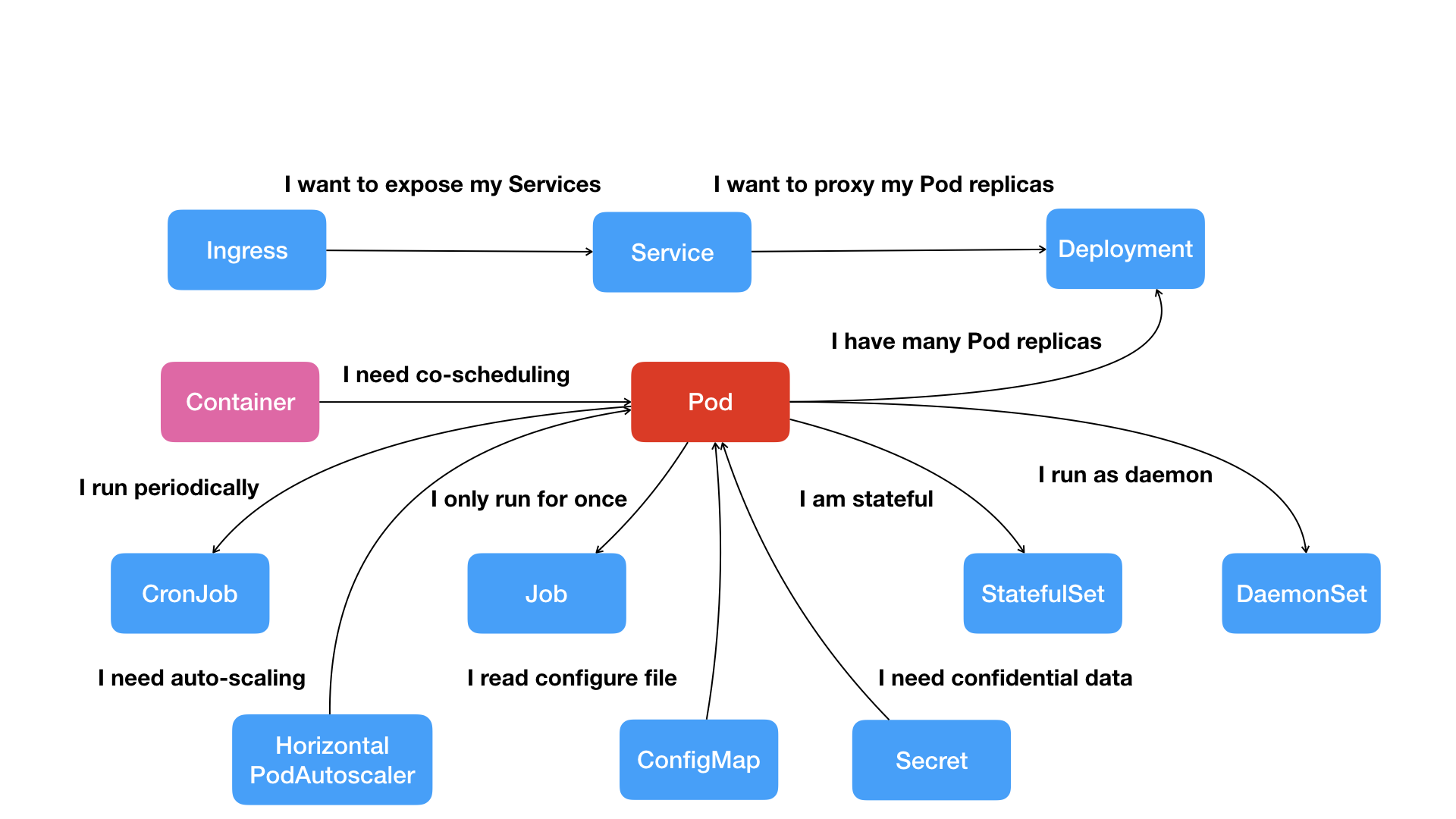
虽然我们已经成功地将一个静态网站成功地在Kubernetes里部署起来了,但还有很多细节可以完善。我们就在这一节里逐步优化。
1. ConfigMap
问题最明显的是。重温一下我们静态网站之前使用的Dockerfile:
1
2
3
| FROM nginx:alpine
COPY default.conf /etc/nginx/conf.d/default.conf
COPY ./dist /usr/share/nginx/html
|
首先是Nginx配置default.conf。
网站的源代码不应该干涉网站怎么部署。到底部署在Apache,Nginx还是Node.js,是否要在部署的时候添加自定义Header,都不该是开发者关注的事情。我们也不希望修改网站的timeout配置还需要动到源代码。从耦合性的角度来看,这个Nginx网站的配置文件不应该放到源代码中。
对于这类配置文件,Kubernetes里有专门的对象ConfigMap来保存。
从ConfigMap这个名字就可以猜得到,它存储的是配置信息,存储的格式是Map类型,即键值对。
配置信息可以是像本篇中的Nginx config配置,可以设置环境变量,可以是Java的properties和application.yml配置文件,可以是Redis和MySQL的配置文件。它很适合需要在一套Kubernetes集群上部署多个环境(例如特性分支/sit/uat)的情况。(当然我们的Java应用将使用Spring Cloud Config配置中心,所以目前不会用ConfigMap管理配置)
本篇POC的ConfigMap如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| apiVersion: v1
kind: ConfigMap
metadata:
name: poc-web-config
labels:
app: poc-web
data:
default.conf: |
server {
listen 80;
server_name localhost;
charset utf-8;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
|
default.conf为key(键),下面的内容为value(值)。结构非常简单。
在Kubernetes中,ConfigMap是一种特殊的Volume(卷):Projected Volume。可以认为ConfigMap是Kubernetes中的数据被投射(Project)到容器中的。
关于Volume我们会在后续展开讨论,这里只是先提一下:要在容器中使用volume,需要先在spec中定义,然后mount到容器中。所以添加了ConfigMap后的Deployment定义YAML如下: