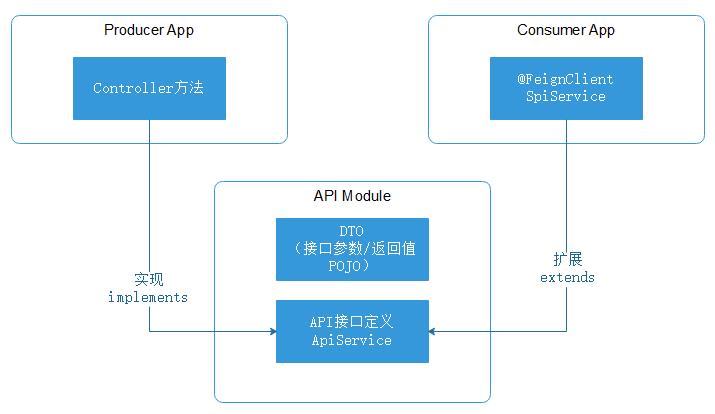
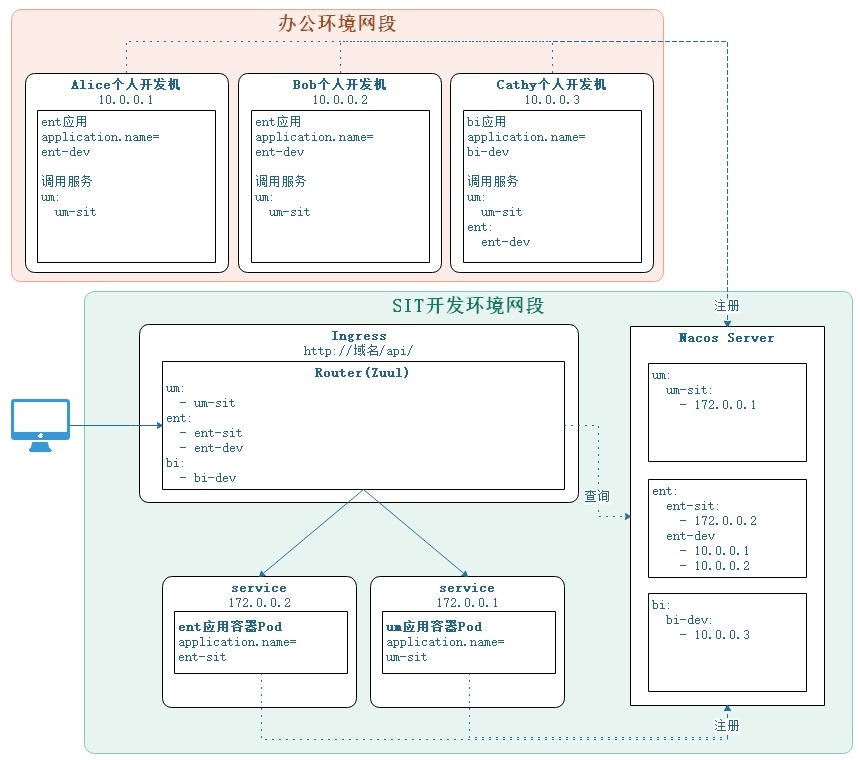
疫情期间积累了一些远程办公条件下的项目管理经验,稍微整理一下。我司从企业文化到网络硬件,不太具备远程办公的基因,要补课的地方就额外多。
1. 按小团队划分并设定第一责任人
亚马逊CEO贝索斯提到过一个原则:如果两个披萨饼都喂不饱一个团队,那么这个团队可能就太大了。按照这个逻辑,我的团队可能只能容纳两个人。。。
玩笑开完了。但事实就是,对于一般人来说,能较好管理5~6个就已经是不错了。当团队人数超过这个规模,需要将团队拆分为6-10人的小团队规模,增加汇报层级,才能管得过来。
每个小团队可以包含前端、后端和测试,而数据库、UI等共享资源单独一个团队。
对每个小团队需要指定一个第一责任人(以下简称“责任人”)。这个责任人需要有以下的素质:
- 对小团队成员知根知底
- 快速响应的执行力和跟进能力
- 对任务目标有充分的理解
2. 通知走大群,信息收集走小群
2.1 通知
远程办公期间的通知事项会比较多。邮件通知方式不能确保所有人都会在第一时间查看邮件。
通过即时通信的群通知,可以确保绝大部分人都能第一时间看到并响应。
即时通信大群的注意点: