1.保理的概念
保理,从本质上来说,就是应收账款的融资服务。
举个场景:某桂园向某混凝土公司A采购了2000吨水泥,应收账款100万。但由于账期原因,应收账款是按照季度结算。但公司A因为款项没有即时结清,产生了资金周转问题。于是公司A就将应收账款以折扣价转让给了保理商B。保理商B给供应公司A提供了融资,并通知某桂园回款后续不再打给公司A,而是打给保理商自己。季末某桂园将回款打给了保理商B。保理商B在融资和回款的差价里赚到了收益。
整个流程可以参见下图
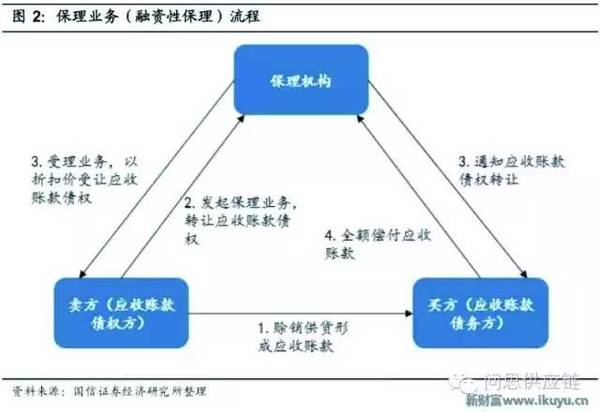
在这个最基础的流程中,有三方:
- 卖方:某混凝公司A,也可以称为债权方、上游
- 买方:某桂园,也可以称为债务方、下游
- 保理商:分为商业机构进行的商业保理和银行保理
1.1 正向保理和反向保理
保理这个概念产生的时候,都是由拥有融资需要的卖方主动发起的。但卖方拿到融资却不供货转身跑路的情况,也不是不会发生。这种情况下,买方当然也不会为没有收到的货而白白付钱。保理为了尽量避坏账,会对卖方的资质和规模进行要求。
但现实中很常见的情况是:上游的卖方是中小企业,无法达成资质规模要求,尽调难度也很大;而下游买方是龙头企业,拥有较高的资信程度。为了在这种场景下也能让保理商放心融资,会由卖方(混凝土公司A)找买方(某桂园)做担保,由买方主动发起保理申请。买方为了保证上游供应链的稳定,出面找保理商做担保:公司A确实是我的上游供应商,我们有商务合作。如果你能信得过我的话(大企业的授信担保),就给公司A融资,然后在一定时间段后到我这里兑回款。保理商相信了A的资信,给公司A提供了融资。
在这里出现了一个核心企业的概念。核心企业是供应链中的概念,是供应链中的关键节点,资信程度较高(AA+是基本门槛)。
在保理流程中,核心企业是保理的发起方。核心企业的类型也是区分正向保理和反向保理的关键判断因素。核心企业是卖家,就是正向保理;核心企业是买家,就是反向保理。这里的“正”和“反”指的是相关交易链的方向。