1. 引子
近10年,开发过一个很简陋的舆情监控平台。大致的架构就是用爬虫从新浪新闻、微博、微信公众号等平台爬取新闻,存储到ElasticSearch中。对于每一条新闻的内容,基于一个负面词库(比如“爆雷”、“下跌”等词),一个公司名+公司高管名字的词库,根据一个自创的算法计算在新闻中的出现次数和关联性,由此判断这篇新闻是否是公司相关的负面舆情新闻。
现在想来,其实就是用稀疏向量检索的方式,企图模拟稠密向量检索的语义识别效果。当时实测下来整体效果还不错。但对于包含了否定词,以及讽刺、反话的内容,识别效果不佳。
本文先比较稀疏向量和稠密向量的差别,然后介绍稠密向量的生成、相似度比较,以及检索方式。然后介绍了阿里云上的向量数据库。
2. 传统关键词检索与稀疏向量
2.1 传统检索方式
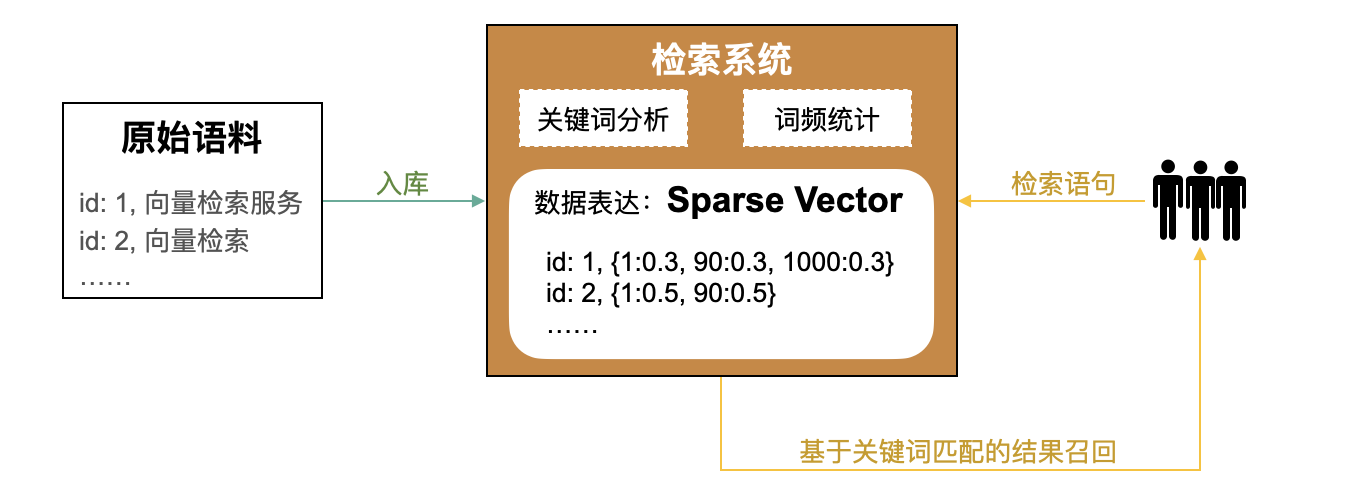
在信息检索领域,“传统”方式是通过关键词进行信息检索,其大致过程为:
- 对原始语料(如网页)进行关键词抽取。
- 建立关键词和原始语料的映射关系。常见的方法有倒排索引、TF-IDF、BM25等方法,其中TF-IDF、BM25通常用稀疏向量(Sparse Vector)来表示词频。
- 检索时,对检索语句进行关键词抽取,并通过步骤2中建立的映射关系召回关联度最高的TopK原始语料。
2.2 常见稀疏向量算法
2.2.1 词袋(BOW)模型
词袋模型(Bag-of-words model,BOW),BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。
以下面的句子为例:
1 | John likes to watch movies. Mary likes too |
将上面的两句话中看作一个文档集,列出文档中出现的所有单词(忽略大小写与标点符号),构造一个字典:
1 | {"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10} |
将句子向量化,维数和字典大小一致,第 ii 维上的 数值 代表 ID 为 ii 的词语在这个句子里出现的频次:
1 | # 第一个文本 |
缺点:
- 不能保留语义:不能保留词语在句子中的位置信息,“你爱我” 和 “我爱你” 在这种方式下的向量化结果依然没有区别。“我喜欢北京” 和 “我不喜欢北京” 这两个文本语义相反,利用这个模型得到的结果却能认为它们是相似的文本。
- 维数高和稀疏性:当语料增加时,那么维数也会不可避免的增大,一个文本里不出现的词语就会增多,导致矩阵稀疏
2.2.2 TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
公式:
1 | TF-IDF(t,d)=TF(t,d)×IDF(t) |
参数:
- TF(词频):词 tt 在文档 dd 中出现的频率。
- IDF(逆文档频率):衡量词 tt 的普遍重要性(越少文档包含该词,IDF 越高)。
2.2.3 BM25
BM25(Best Matching 25)是一种基于统计学的文本相似度评分算法,用于计算查询和文档之间的相关性。
在早期研究中,研究人员尝试了多种参数组合和模型变体,并为不同版本赋予了编号(如 BM11、BM24、BM25 等)。BM25 是其中表现最优的版本之一,因此被广泛采用并成为标准算法名称。
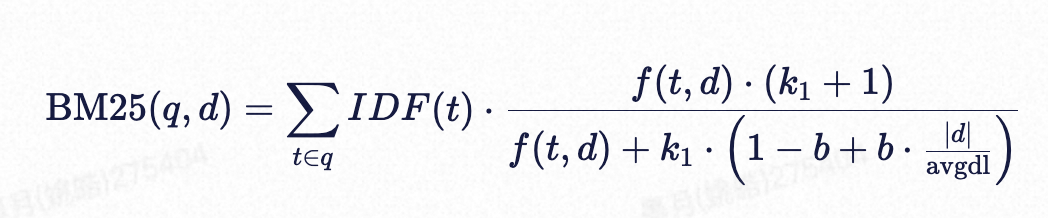
参数:
- f(t,d):词 tt 在文档 dd 中的频率。
- ∣d∣:文档 dd 的长度。
- avgdl:文档集合的平均长度。
- k1,b:可调参数(通常 k1≈1.2−2.0,b≈0.75)。
BM25 对 TF-IDF 的改进:
- 文档长度归一化:BM25 通过 b 参数控制长文档的惩罚(避免长文档因词多而被误判为更相关)。
- 词频饱和:BM25 通过 k1 参数限制词频的权重增长(避免高频词过度影响结果)。
- 动态调整:BM25 的参数 k1、b 允许针对不同数据集优化,而 TF-IDF 固定不变。
BM25 是对 TF-IDF 的扩展,针对检索排序问题进行了优化,是现代搜索引擎(如 Elasticsearch)的基础算法之一。
2.3 稀疏向量的存储方式
稀疏向量只存储非零元素及其维度的索引,通常以{ index: value} 的键值对表示。
如:
1 | [{2: 0.2}, ..., {9997: 0.5}, {9999: 0.7}] |
2.4 稀疏向量特征总结
- 原理:映射成一个高维(维度一般就是 vocabulary 空间大小)向量
- 数据特征:向量的大部分元素都是 0
- 检索机制:只为那些输入文本中出现过的 token 计算权重。非零值表明 token 在特定文档中的相对重要性。
- 检索特征:检索速度快
- 适用场景:需要精确匹配关键词或短语
- 局限性:无法对语义进行理解。例如,检索语句为“浙一医院”,经过分词后成为“浙一”和“医院”,这两个关键词都无法有效的命中用户预期中的“浙江大学医学院附属第一医院”这个目标。
3. 稠密向量
3.1 Embedding模型与稠密向量
Embedding模型的核心,是在将高维数据(如文本、图像、音频等)映射到低维的连续向量空间中。
举一个简单的例子:可以将狗的品种按照平均大小、毛色,毛发量、听话程度等,都以数值形式打个分。这样每个狗品种就可以形成一个数组,如:拉布拉多:[0.9, 0.8, -0.5,0.7]
相近品种的狗特征相近,那么在多维空间的距离也就接近。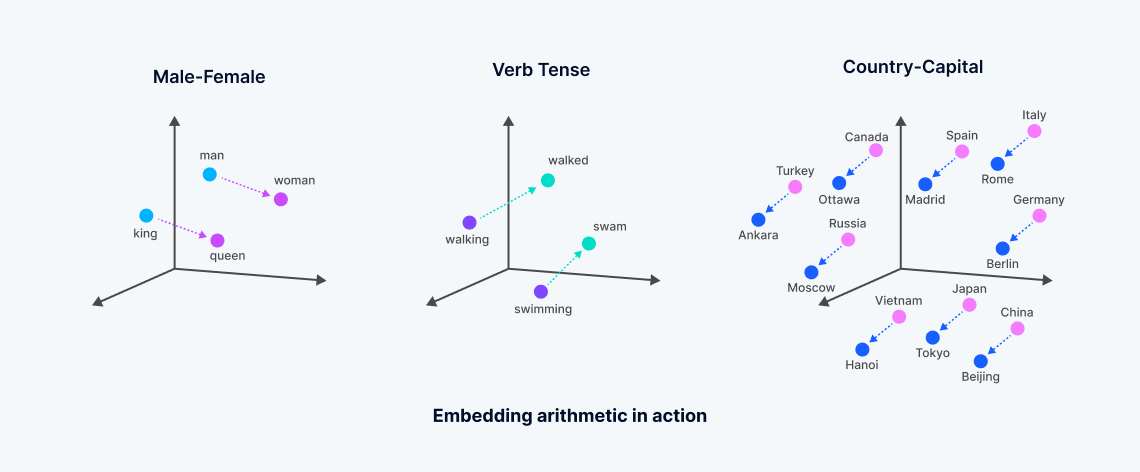
vector embedding,或称向量表示/向量嵌入,通过 Embedding 模型生成的数据表示。狭义上特指 稠密(Dense) 向量。vector embedding通常还包含作为后续任务(如分类、聚类、检索)用途的含义。
关键特征:
- 高维空间:一个维度能代表一个特征或属性,高维意味着分辨率高,能区分细微的语义差异;
- 数值表示:一个 embedding 一般就是一个浮点数数组,所以方便计算。
3.2 稠密向量特征总结
- 数据特征:embedding 向量的大部分字段都非零
- 维度特征:相比 sparse embedding 维度要低很多
在这个多维空间中,意义相关的词被放置得更近。
稠密向量本质上是对语义的压缩,具有语义理解能力。
3.3 稠密向量生成模型原理:BERT & OpenAI text-embedding-3
从稠密向量模型的训练方法,可以大致理解为什么稠密向量具有语义理解能力。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,通过双向上下文建模和自监督学习,能够生成高质量的文本嵌入。其训练过程分为两个主要阶段:预训练(Pre-training) 和 微调(Fine-tuning)。
其中的预训练部分中,BERT通过两个自监督任务在大规模无标签语料上进行预训练,目标是让模型学习语言的通用表示。
Masked Language Model (MLM)
- 目标:预测被随机遮蔽的词。
- 实现方式:输入句子中随机遮蔽15%的词(例如,将“the cat is on the mat”变成“the [MASK] is on the mat”)。模型根据上下文预测被遮蔽词的原始内容。
- 被遮蔽词中有80%替换为[MASK],10%保留原词,10%替换为随机词(防止模型过度依赖[MASK]标记)。
Next Sentence Prediction (NSP)
- 目标:判断两段文本是否连续。(50% 正例,50% 负例)。
- 实现方式:输入句子对(Sentence A, Sentence B),其中50%的时间B是A的下一句,50%是随机句子。模型通过[CLS]标记的输出判断两段是否连续。
OpenAI的text-embedding-3还增加了对比学习任务、多任务学习等,更注重语义对齐和推理效率,无需微调。
3.4 百炼text-embedding-v3
https://help.aliyun.com/zh/model-studio/embedding,是通义实验室基于LLM底座的多语言文本统一向量模型。灵活的向量维度选择:提供 1024、768、512、256、128和64六种维度选择,维度越高,语义表达精度越高。支持稠密向量(dense)和离散向量(sparse)。
Java SDK调用范例:
1 | public List<Float> textEmbed(String text) { |
3.5 其他文本向量化模型
魔搭社区-CoROM文本向量
模型ID:damo/nlp_corom_sentence-embedding_chinese-base
维度:768
度量方式:Cosine
适用领域:中文-通用领域-base
更多信息参考:https://modelscope.cn/models/iic/nlp_corom_sentence-embedding_chinese-base
魔搭社区-GTE文本向量
模型ID:damo/nlp_corom_sentence-embedding_chinese-base
维度:768
度量方式:Cosine
适用领域:中文-通用领域-base
更多信息参考:https://modelscope.cn/models/iic/gte_sentence-embedding_multilingual-base
范例在上一章已提供,可参考。
魔搭社区-Undever多语言通用文本表示模型
模型ID:damo/udever-bloom-560m
维度:1024
度量方式:Cosine
更多信息参考:https://modelscope.cn/models/iic/udever-bloom-560m
魔搭社区-StructBERT FAQ问答
模型ID:damo/nlp_structbert_faq-question-answering_chinese-base
维度:768
度量方式:Cosine
适用领域:中文-通用领域-base
更多信息参考:https://modelscope.cn/models/iic/nlp_structbert_faq-question-answering_chinese-base
Jina Embeddings v2模型
模型名称:jina-embeddings-v2-small-en
维度:768
度量方式:Cosine
https://jina.ai/embeddings/
3.6 多模态向量化模型
此外,也有多模态也可以使用multimodal-embedding-v1。详情参考:https://help.aliyun.com/zh/model-studio/developer-reference/multimodal-embedding-api-reference
文本语义识别体验
下面的代码是使用GTE文本向量化模型生成向量,归一化后进行相似度打分。
1 | import torch.nn.functional as F |
结果是:
1 | [[0.6987984776496887, 0.694797933101654, 0.47736865282058716, 0.6109740734100342, 0.7921578288078308, 0.7704585790634155]] |
我们将结果从低到高排个序:
- 常识:0.47736865282058716
- 吃完苹果可以吃香蕉吗?:0.6109740734100342
- 海鲜:0.694797933101654
- 牛奶:0.6987984776496887
- 不可以喝牛奶:0.7704585790634155
- 可以喝牛奶:0.7921578288078308
从结果可以看到,对原始问题的回答得到了高分,并且符合生活常识的回答得到了最高分。
4. 向量相似度度量
相似度量用于衡量向量之间的相似性。
主要的度量方式为3种:
- 余弦相似度
- 欧式距离
- 点积相似度
4.1 欧式距离(Euclidean Distance)
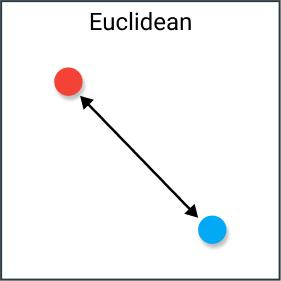
欧式距离可解释为连接两个点的线段的长度。欧式距离公式非常简单,使用勾股定理从这些点的笛卡尔坐标计算距离。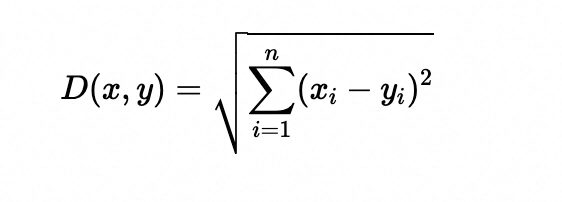
4.2 余弦相似度(Cosine Similarity)
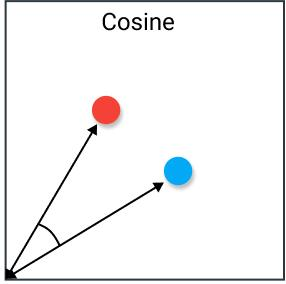
余弦相似度是指两个向量夹角的余弦。
特点:如果将向量归一化为长度均为 1 的向量,则向量的点积也相同。余弦相似度经常被用作抵消高维欧式距离问题。当我们对高维数据向量的大小不关注时,可以使用余弦相似度。
场景:对于文本分析,当数据以单词计数表示时,经常使用此度量。适用于不同长度的文本计算语义相似性。
4.3 点积相似度
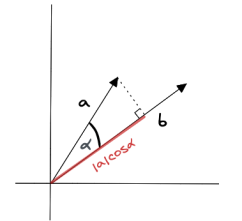
通过将两个向量的对应分量相乘后,将每个计算值相加求和得出结果,从而进行相似度检验。
向量a和b的点积计算公式如下:
点积会受到向量长度和方向的影响。当两个向量长度相同但方向不同时:如果两个向量方向相同,则点积计算结果较大;如果两个向量方向相反,则点积计算结果较小。
4.4 Milvus中的度量类型
Milvus 以上几种度量类型都支持,但名称有些不同:
- 欧氏距离:L2
- 内积/点积相似度:IP
- 余弦相似度:COSINE
可以在搜索的时候设置search_params来指定度量类型:1
2
3
4
5
6
7
8
9search_params = {
"metric_type": "L2"
}
result = milvus_client.search(
collection_name=collection_name,
data=[vectors_to_search],
limit=1,
search_params=search_params,
output_fields=["id", "text"])
5. 检索算法与向量索引
5.1 KNN
k近邻算法全称是 k-nearest neighbors algorithm,简称kNN。
KNN是一种暴力检索算法。按距离排序,选取前 K 个。
优点:
- 绝对最近
缺点: - 计算复杂度高:需遍历所有训练样本,时间复杂度为 O(n)。
- 内存消耗大:需存储整个训练集。
在人脸识别的场景中经常要求100%的召回率,这种情况下一般直接暴力计算。
5.2 ANN
与通常非常耗时的精确检索相比,ANNS 的核心理念不再局限于返回最精确的结果,而是只搜索目标的近邻。ANNS 通过在可接受的范围内牺牲精确度来提高检索效率。
以其中常见的基于图的检索方法为例。
已有的向量数据库内容就是图中的点,ANN的任务就是对给定一个点找到距离最近的点。那么如果每个点都知道离自己近的点,那么是不是就可以沿着这个连接线找到相近的点了。这样就避免了与所有数据计算距离。这就是基于图算法出发点。
NSW(navigate small world),漫游小世界算法。对于每个新的传入元素,我们从结构中找到其最近邻居的集合(近似的 Delaunay 图, 就是上面的右图)。该集合连接到元素。随着越来越多的元素被插入到结构中,以前用作短距离边现在变成长距离边,形成可导航的小世界。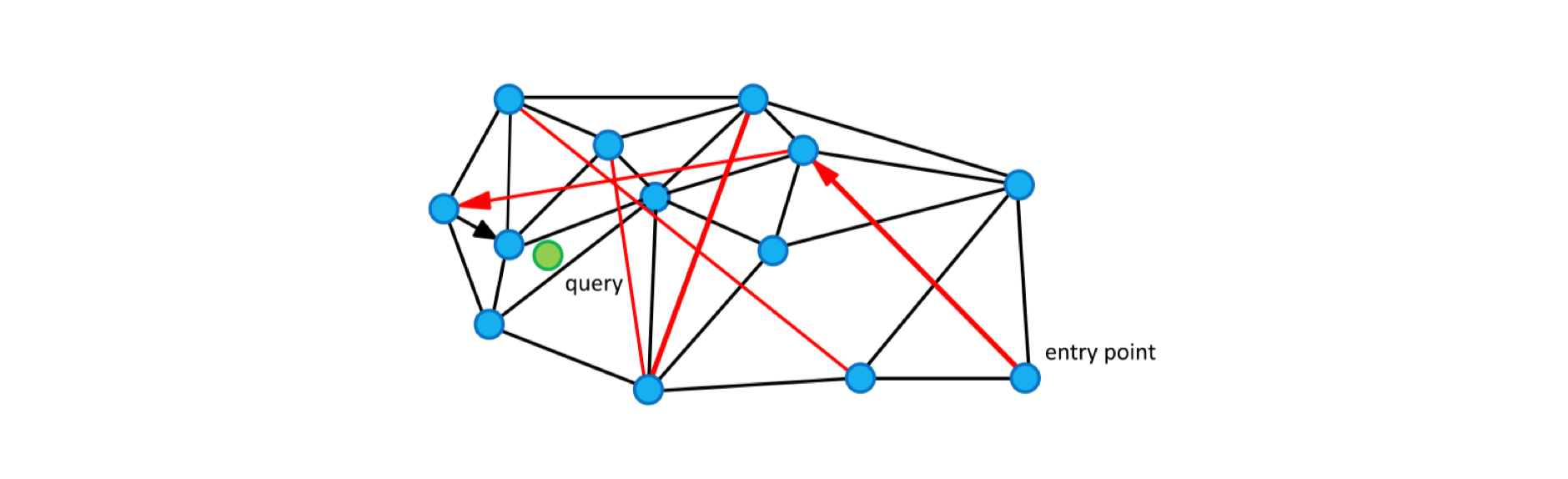
圆(顶点)是度量空间中的数据,黑边是近似的 Delaunay 图,红边是用于对数缩放的长距离边。箭头显示从入口点到查询的贪心算法的示例路径(显示为绿色)。
HNSW(Hierarchical Navigable Small World)是对 NSW 的一种改进。HNSW 借鉴了跳表的思想,根据连接的长度(距离)将连接划分为不同的层,然后就可以在多层图中进行搜索。在这种结构中,搜索从较长的连接(上层)开始,贪婪地遍历所有元素直到达到局部最小值,之后再切换到较短的连接(下层),然后重复该过程,如下图所示: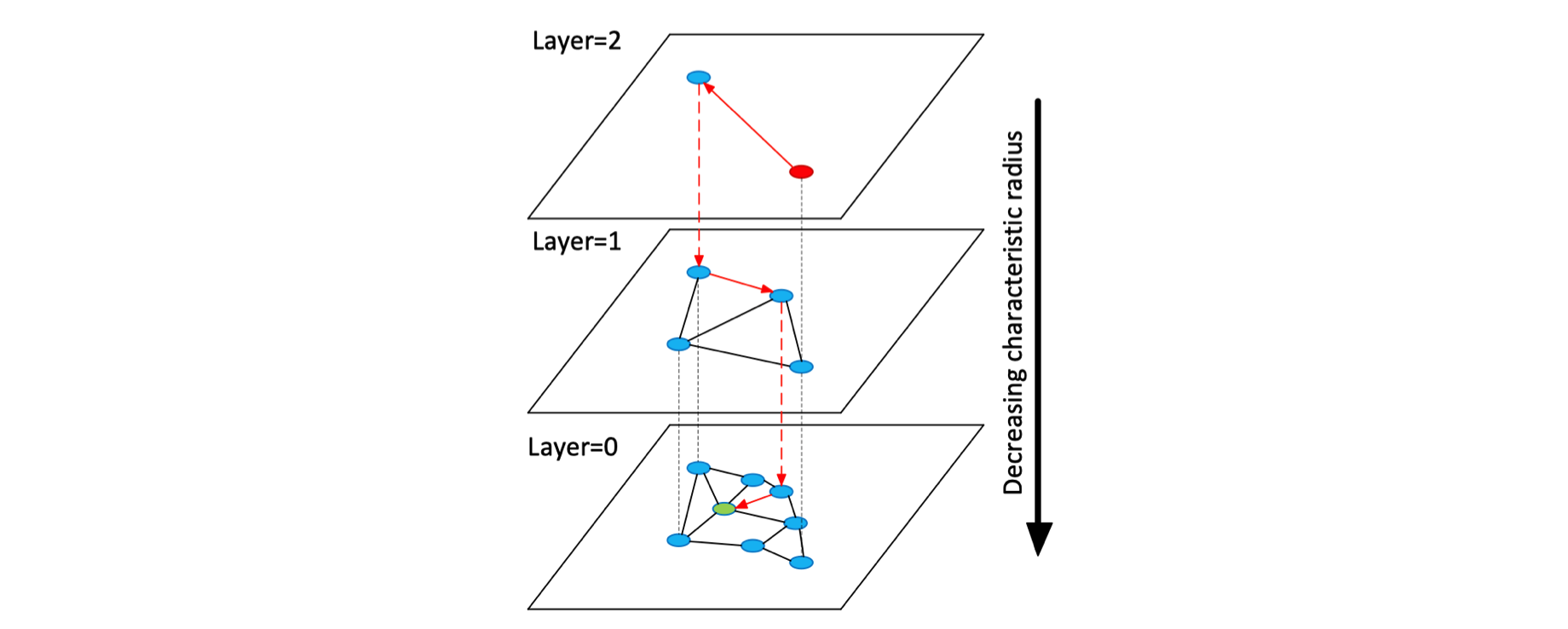
5.3 Milvus支持的索引
- 平面: 数据集相对较小,需要 100% 的召回率
- IVF_FLAT: 高速查询,要求尽可能高的召回率
- IVF_SQ8: 极高速查询,内存资源有限,可接受召回率略有下降
- IVF_PQ: 高速查询,内存资源有限,可略微降低召回率
- HNSW: 极高速查询,要求尽可能高的召回率,内存资源大
- HNSW_SQ: 非常高速的查询,内存资源有限,可略微降低召回率
- HNSW_PQ: 中速查询,内存资源非常有限,在召回率方面略有妥协
- HNSW_PRQ: 中速查询,内存资源非常有限,召回率略有下降
- SCANN: 极高速查询,要求尽可能高的召回率,内存资源大
6. 向量数据库主要概念
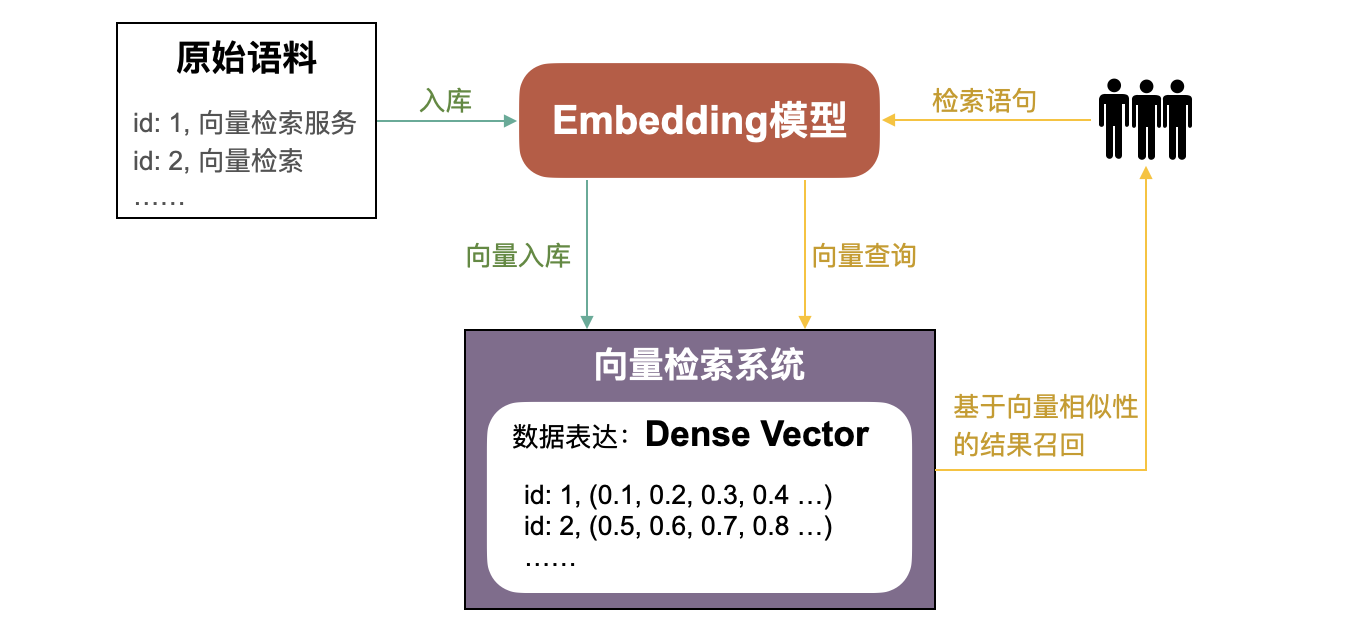
6.1 基于稠密向量的语义检索
6.2 向量数据库与传统关系性数据库概念对比
无论DashVector,还是Milvus,本质上更接近数据库。主要能力包含几项:
- 创建实例/DB
- 创建表(Collection)
- 插入数据(实体/Doc),支持分区
- 创建索引加速查询
- 搜索,支持标量字段过滤
- DB: DB
- Collection: 表(Table), Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。
- Partition: 分区表(Partitioned Table), 将 Collection 分割为多个子集,便于管理和查询性能优化(如按时间或业务逻辑分区)。
- Field: 列(Column), Milvus的Field包括标量字段(如字符串、整数)和向量字段。
- Document: 行(Row), 表中的一条记录,对应 Milvus 中的一组向量字段值+标量字段值。
- Vector Index: B-Tree 索引, 用于加速向量相似性搜索的索引结构(如 HNSW、IVF-PQ);
7. 向量检索服务比较
7.1 自建Milvus vs 云Milvus
Milvus架构: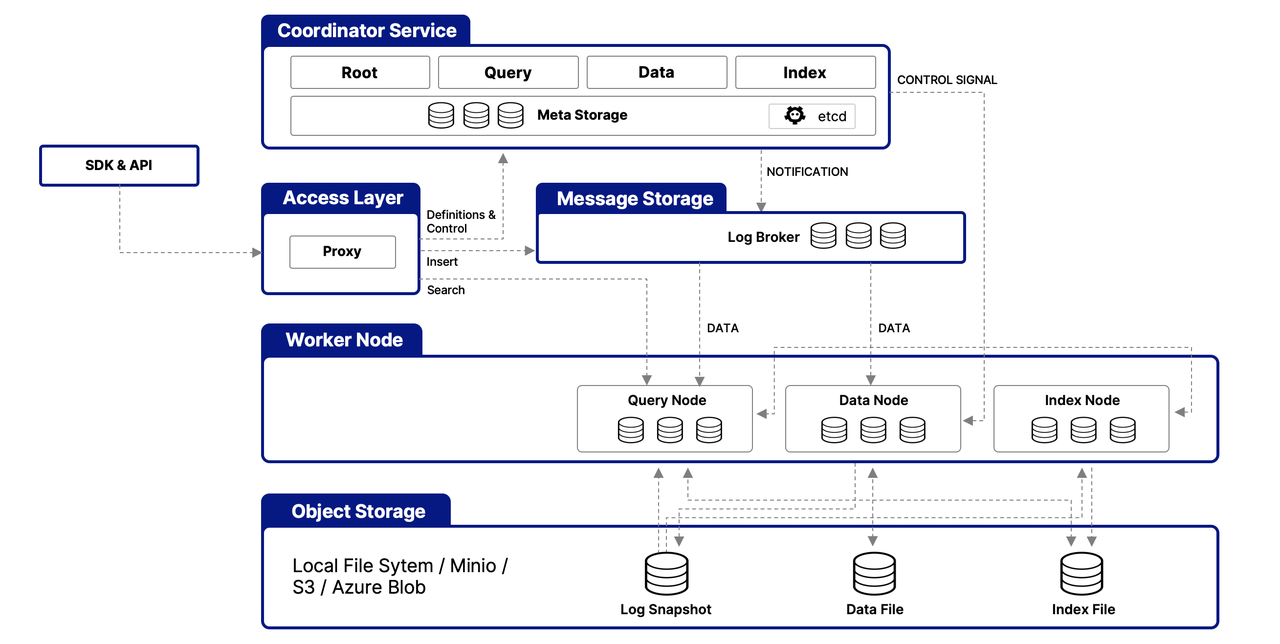
对于自建Milvus和云Milvus,官方的比较参考:[https://help.aliyun.com/zh/milvus/product-overview/comparison-between-alibaba-cloud-milvus-and-ecs-self-built-milvus]
其实也和云数据的优点类似:
- 开箱即用,拉起方便
- 弹性伸缩
- 白屏化运维和管控
- 稳定性
- 产研支持
7.2 云Milvus vs DashVector
DashVector相比Milvus:
- 简化概念,包括Schema、索引等
- 面向用户:做快速PoC,数据量小,性能要求不特别高
- 灵活度: 低。没有索引方式选择。
- 上手难度: 低
之前DashVector还有一个优势:除了包年包月之外,支持按量付费。而之前云Milvus只有包年包月,最低规格每个月约5K,对开发者上手还是有些门槛和肉疼的。不过当前云Milvus也支持按量付费了。
8. 主要场景
8.1 简单语义匹配
将用户输入的文字和数据库里的文字进行语义匹配,寻找最接近的匹配结果的场景。
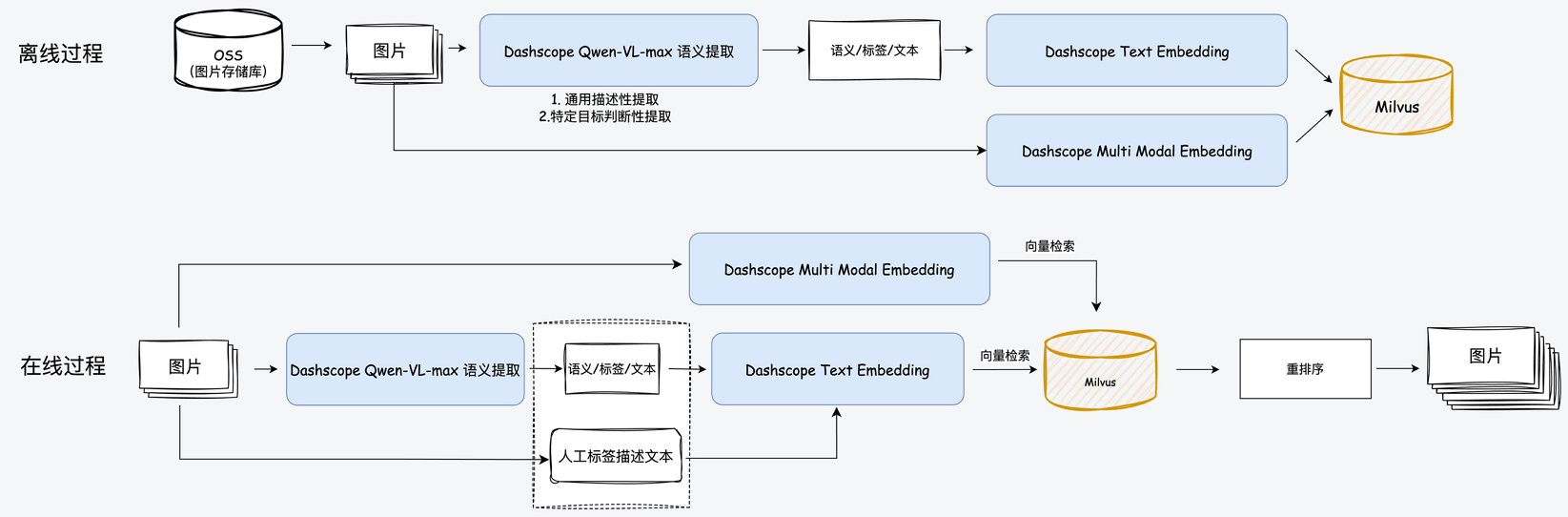
8.2 多模态检索
- 以文搜图:输入文本查询,搜索最相似的图片。
- 以文搜文:输入文本查询,搜索最相似的图片描述。
- 以图搜图:输入图片查询,搜索最相似的图片。
- 以图搜文:输入图片查询,搜索最相似的图片描述。
8.3 RAG智能问答
向量化的最通用业务场景之一,就是RAG知识库。先将文档切分为文本块,然后将文本块生成Embedding模型。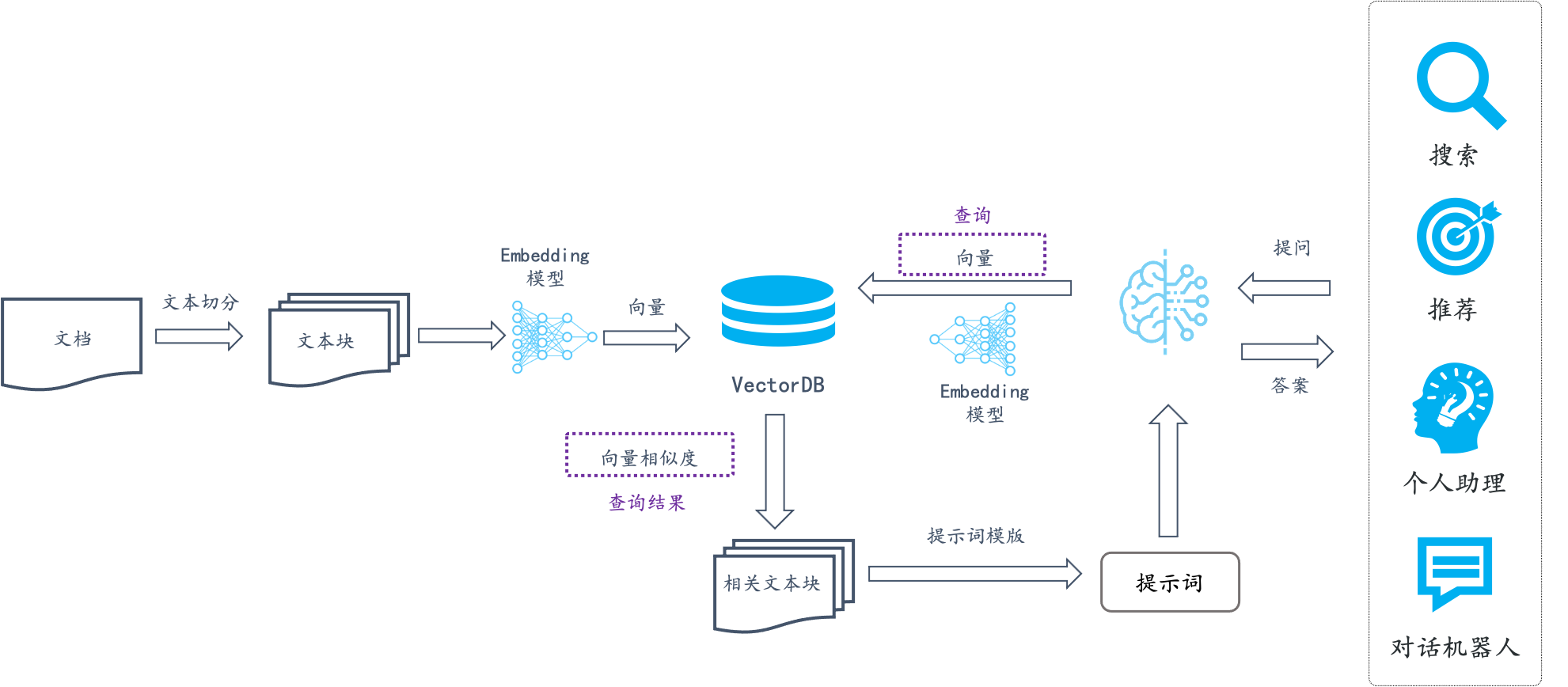
- 知识库预处理:您可以借助LangChain SDK对文本进行分割,作为Embedding模型的输入数据。
- 知识库存储:选定的Embedding模型(DashScope)负责将输入文本转换为向量,并将这些向量存入阿里云Milvus的向量数据库中。
- 向量相似性检索:Embedding模型处理用户的查询输入,并将其向量化。随后,利用阿里云Milvus的索引功能来识别出相应的Retrieved文档集。
- RAG(Retrieval-Augmented Generation)对话验证:您使用LangChain SDK,并将相似性检索的结果作为上下文,将问题导入到LLM模型(本例中用的是阿里云PAI EAS),以产生最终的回答。此外,结果可以通过将问题直接查询LLM模型得到的答案进行核实。
提示词范例:
1 | from dashscope import Generation |
{context}
1
2
3
4
5
我的问题是:{question}。
'''
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text
适用场景:
- 客户希望更多把控全链路
- 客户希望进一步降低响应RT
8.4 更多场景想象
- 加速药物发现:在制药行业,向量嵌入可以编码化合物的化学结构,通过测量其与目标蛋白质的相似性来识别有前景的药物候选物。这加速了药物发现过程,通过专注于最有可能的线索来节省时间和资源。
- 异常检测:在欺诈检测、网络安全和工业监控等领域,向量嵌入在识别异常模式方面起着重要作用。通过将数据点表示为嵌入,可以通过计算距离或不相似性来检测异常,从而实现对潜在问题的早期识别和预防措施。