ARTS中的 Review英文技术文章点评 和 Share技术文章分享,先试点按照月为单位,每月发一篇汇总吧。每篇写一小段感想。
关于英文技术文章来源,从v2ex的推荐,找到了DevURLs – A neat developer news aggregator的文章聚合网站。但感觉这些文章大多很短,看得不太过瘾。所以在尝试了两周后,改为根据本周关注的技术点,用英文关键字Google,选择搜索结果中质量比较高的。
Review
eBPF for Cloud Computing - DZone
https://dzone.com/articles/ebpf-for-cloud-computing
eBPF这个术语看到过好几次,找了一篇入门介绍。主要是针对eBPF和K8S结合的场景,包括网络可观测性、安全、性能监控等用途。
eBPF的主要优势在于不用开发Linux内核模块,也能在内核执行。这点使其很适合K8S,用于包含Calico、Cilium在内的开源项目。
Improving language understanding by generative pre-training[J].
在B站李沐视频和内网解读文章的辅助下,读了GPT-1的论文。除了论文本身的知识点外,有2个感受:
- 学习了标准论文的结构。
- 好的配图对于理解很重要。我指的就是Transformer原理的那张经典架构图。
A Beginner’s Guide to Vector Embeddings
https://www.timescale.com/blog/a-beginners-guide-to-vector-embeddings/
这周在做灵积的DashScope和DashVector的Demo,对其中用到的embeddings概念感兴趣,就找了一篇相关的科普。记录一下科普文中比较感兴趣的点:
- Embeddings和Vector的关系:Embeddings可以表现为Vectors,可以生成Vectors,但Vectors本身的概念范围更加广泛。
- Embeddings的类型,除了Word外,还包含Sentence、Document、Graph、Image、Audio,还有Product。Product可以用于产品推荐,应该在淘宝中已经运用了。
- Vector Embeddings如何存储:作者推荐使用PG
关于Embeddings、Zero Shot、Few Shot、Fine tunning的使用场景,也可以参考下图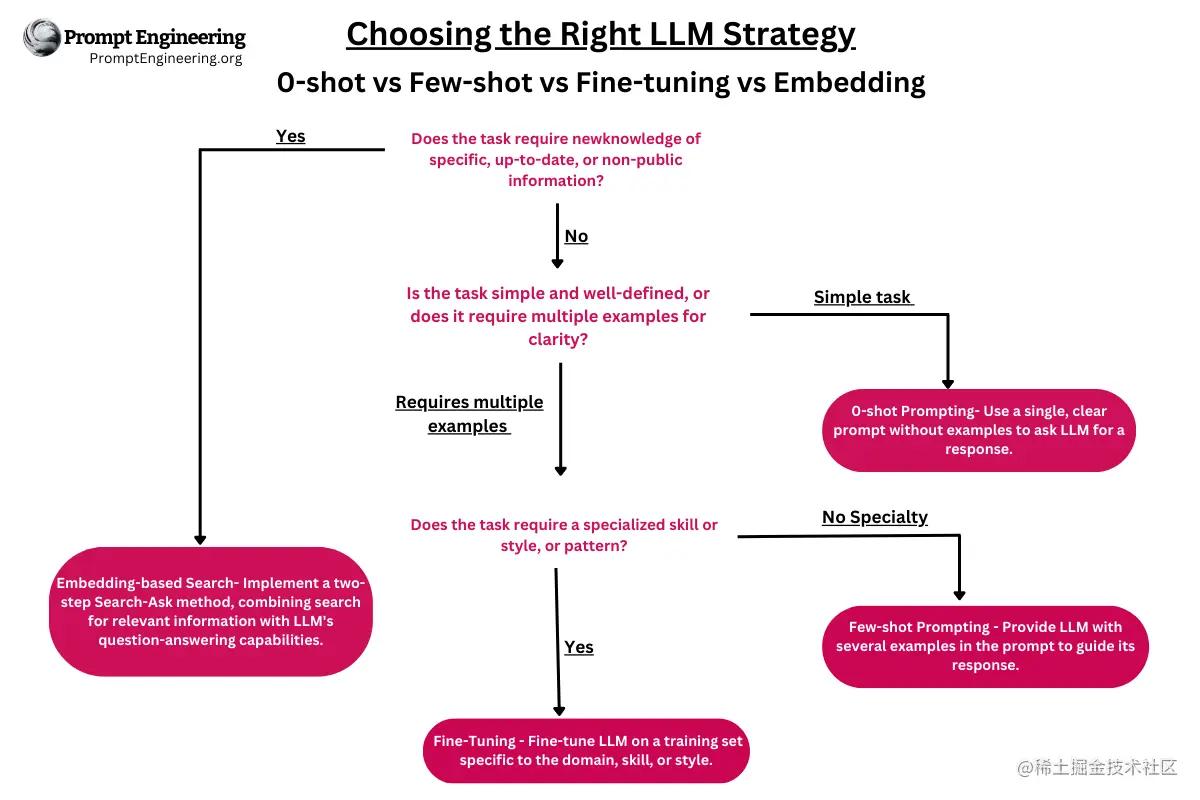
Share
【哔哩哔哩技术】7.2 我们机房断网了!
https://mp.weixin.qq.com/s/KD1cvp6thMXM8LkrRUoslw
B站技术的文章通常干货不少。
之前在网络方面的常识比较缺乏,借这篇也补习了下POP(网络接入点)的概念。
也重温了下南北向流量管控和东西向流量管控的策略区别:
- 南北向流量:指的是从外部(互联网)进入数据中心或云平台内部,以及从内部向外发出的流量。
- 东西向流量:东西向流量指的是在同一数据中心内部或云平台内不同服务器、服务之间流动的流量。
南北向包含:
- 防火墙与安全组
- 入侵检测与防御系统(IDS/IPS)
- SSL/TLS卸载与检查
- 边界网关协议(BGP)路由控制
- DDoS防护
东西向包含:
- 软件定义网络(SDN)
- 网络策略控制器:如Kubernetes中的NetworkPolicy
- 服务网格(Service Mesh):如Istio、Linkerd等
- API网关与服务间认证
人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型 / 人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状
https://www.mikecaptain.com/2023/01/22/captain-aigc-1-transformer/
https://www.mikecaptain.com/2023/03/06/captain-aigc-2-llm/
这两篇并在一起讲。在查阅GPT的发展历程的过程中,这两篇原阿里同学写的文章,是最详尽的。
通过这两篇,加上B站李沐的视频,我的主要收获是基本把LLM中几个重要概念有了初步了解。我个人重点关注的概念包括:
- Transformer(含编码器与解码器)
- 注意力(Attension)与自注意力机制
- GPT与BERT的关系
- Fine tuning/Zero shot/Few Shot的区别
以前读的几篇GPT的介绍文,我个人最不满意的就是将Few Shot描述得像魔法一样。的确由于LLM的黑盒特性,无法给出非常确切的结论,但业界肯定是有假设的。采用这种神乎其神的介绍方式只会降低GPT的可信度。
而《人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状》这篇中,给出了ICL能力的底层假设是贝叶斯推理,以及提到了很多隐式马尔科夫模型的混合体的数学框架假设。
Way To Prompt系列(1): 为什么大模型连”Strawberry”的”r”都数不对?一招“理由先行”显著提升模型思考能力
这篇是内网的文章,不过命题的来源是外网的几篇文章:
- 为什么AI数不清Strawberry里有几个 r?Karpathy:我用表情包给你解释一下 | 机器之心:https://www.jiqizhixin.com/articles/2024-07-27-5
- 大模型智障检测+1:Strawberry有几个r纷纷数不清,最新最强Llama3.1也傻了-36氪:https://36kr.com/p/2877379178156681
- 一记惊雷:改一下Prompt的输出顺序,就能显著影响LLM的评估结果:https://mp.weixin.qq.com/s/GxX0brkFjlUN9z8oRWJUNw
这几篇深入简出地解释了Tokenization,以及所带来的问题。也介绍了Few Shot和Zero Shot的分别解决办法:
- Few Shot:添加Prompt:“请你先将单词拆分成一个个字母,再用0和1分别标记字母列表中非r和r的位置,数一下一共有几个r”
- Zero Shot:添加Prompt“请一步步思考,以逐级复杂的原则思考问题,最后才得到答案。”,即思维链(Chain-of-Thought,简称CoT)
不用CoT加以限制的的情况下,大模型倾向于先给出一个答案,再给出理由。这个理由很可能是为了圆那个答案编造出来的。
这个引导方式也不禁让我想到教女儿的时候,如果引导她一步步说出自己的思考过程,答案的正确率的确会提高。
总结成四个字:“理由先行”。