从Oracle或MySQL切换到PostgreSQL(以下简称pgsql)后,多少有些不一样的地方需要适应。这里就将和开发相关的一些区别挂一漏万地列举一下。
1. Schema模式
和Oracle与MySQL一样,pgsql中也有TableSpace(表空间),用于定义用来存放表示数据库对象的文件的位置。
但在Schema(模式)的定义上,三者有很大的差别。
对于MySQL,模式与数据库同义。甚至可以用CREATE SCHEMA来创建数据库,效果和CREATE DATABASE一样。
对于Oracle,schema与数据库用户密切相关:
A schema is a collection of logical structures of data, or schema objects. A schema is owned by a database user and has the same name as that user. Each user owns a single schema.
而pgsql中,层次结果如下: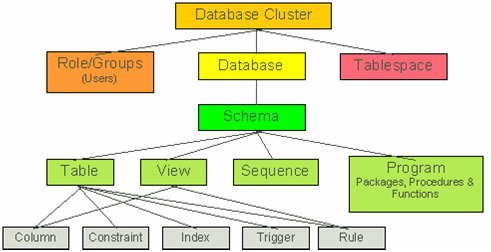
从图中可以看到,schema是database与table中间的一层。可以理解为命名空间类似的概念。当新创建一个数据库时,pgsql会默认创建一个public schema。如果没有指定的话,就是以public schema来操作各种数据对象。 例如:CREATE TABLE products ( ... ) 等同于 CREATE TABLE public.products ( ... )
schema不能互相嵌套。同一个schema下不能有重复的对象名字,但在不同schema下可以重复。
schema与database的差别在于schema不是严格分离的:一个用户可以访问他所连接的数据库中的任意模式中的对象。
对于数据库管理人员来说,还需要了解一下授权相关的差别,但在本文中就略过了。更多可以参考这篇:PostgreSQL · 特性分析 · 逻辑结构和权限体系
1.1 Schema与开发相关
连接url字符串中除了需要指定数据库之外,还需要加一个currentSchema。例如下面的范例中,database是pabem,schema是pabem_um_dev:
1 | jdbc:postgresql://localhost:5432/pabem?currentSchema=pabem_um_dev |
schema可能对需要跨数据源的应用开发带来一些简便。如果需要跨的两个数据源只是同一个数据库的两个schema,就可以去掉连接url中的currentSchema,就可以当单数据源应用来开发了。
参考资料
表空间
默认schema是public,切换执行sql所在schema的语法是:
1 | set search_path to <schema_name> |
2. 自增字段
和MySQL中使用的auto increment不同,PostgreSQL和Oracle类似,都是用sequence(序列)。
sequence的好处在于可以让多张表共享同一个自增序列,但创建起来的确也挺麻烦。所以pgsql还新增了一个语法糖serial。
和数值类型一样,也分为smallserial, serial和bigserial:
| Name | Storage Size | Range |
|---|---|---|
| smallserial | 2 bytes | 1 to 32767 |
| serial | 4 bytes | 1 to 2147483647 |
| bigserial | 8 bytes | 1 to 9223372036854775807 |
2.1 Serial与开发相关
对于自增的id字段,需要在Entity的属性上加上注解:
1 |
3. 数据类型映射
| PostgreSQL数据类型 | Oracle数据类型 | MySQL数据类型 | 备注 |
|---|---|---|---|
| char | char | char | Oracle中char(n)的n表示byte数,而pgsql和mysql中表示字符数。对于中文字无需除以2或除以3 |
| varchar | varchar2 | varchar | 同char |
| text | clob | text | |
| bytea | blob | blob | |
| smallint | number(4) | smallint,tinyint | pgsql中没有tinyint,所以我们的布尔型字段用smallint类型 |
| int | number(9) | int | int是integer的缩写 |
| bigint | number(18) | bigint | |
| decimal | decimal | decimal | decimal与numeric等价,都是SQL标准。我们就统一用decimal |
| date | (无) | date | Oracle没有纯日期类型,date会返回日期和时间 |
| timestamp | timestamp | timestamp | pgsql还有timestampz表示带时区的时间戳 |
参考资料
PostgreSQL: Documentation: 11: 8.1. Numeric Types
4. 常用函数与语法差异
4.1 DUAL
pgsql中的select可以省略from,所以不再需要强制加一个from dual。
4.2 日期和时间
- 当前时间:
now() - 日期转字符串:
select to_char(current_date,'YYYY-MM-dd'); - 时间转字符串:
select to_char(now(),'YYYY-MM-dd HH24:MI:SS');
4.3 字符串
- 拼接:
select 'a'||'b' as col1; - 获取指定字符串的下标:
select position('om' in 'Thomas');
4.4 序列
获取序列下一个值的语法为:nextval('sequence_name')
4.5 行数
1 | ROW_NUMBER() OVER( |
例如:
1 | SELECT |
4.6 NVL(判断为空赋值)
1 | SELECT coalesce(null,0) as col1; |
4.7 分页
PostgreSQL中的分页语法和MySQL类似:
1 | SELECT |
4.8 CRUD语法差异
网上也看到有人整理了一下CRUD语法的差异: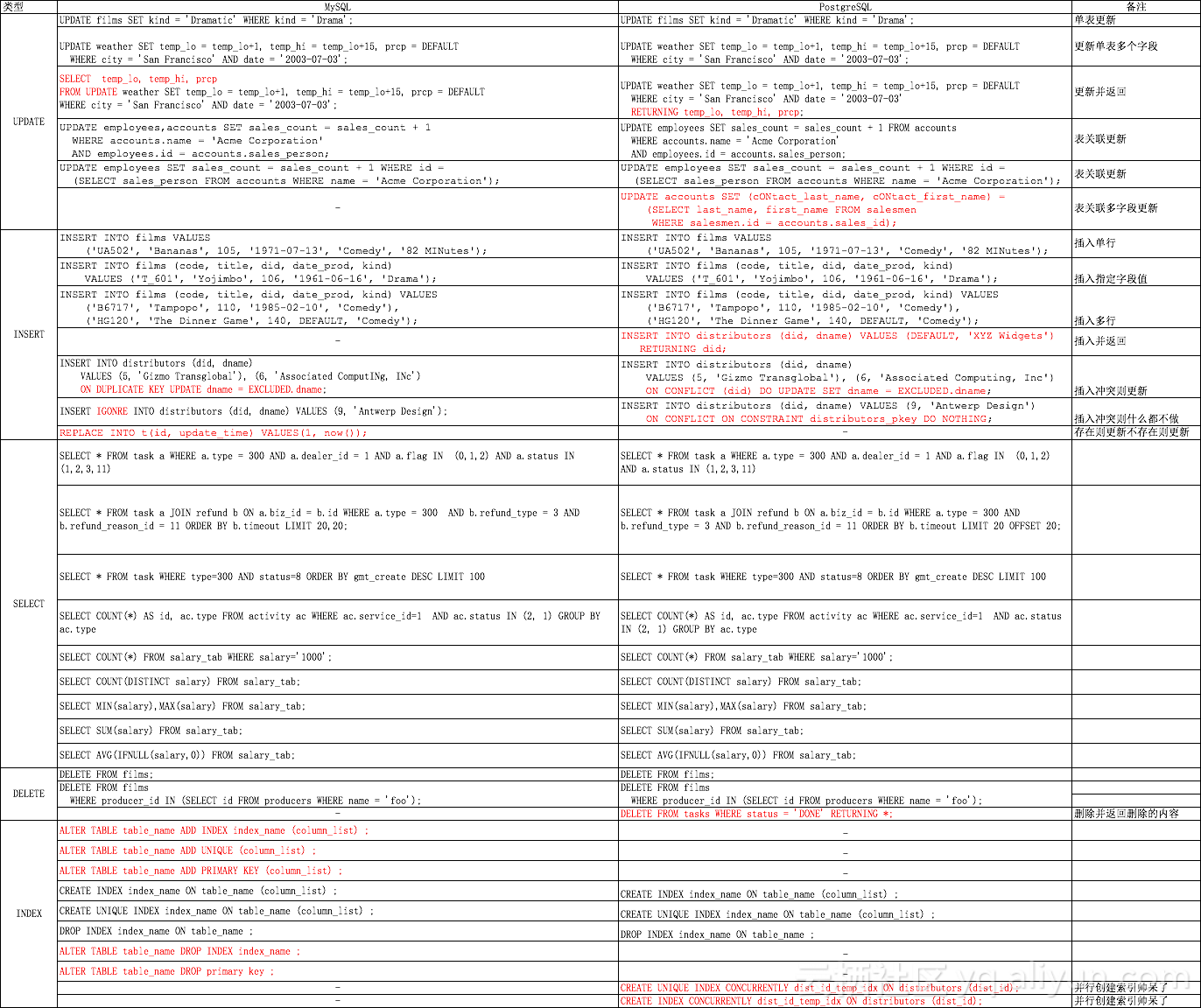
简单总结一下,就是支持插入/更新/删除并返回,以及插入冲突则更新或什么不做。前者从通用性考虑不推荐,后者MyBatis Plus也封装了一个,不一定需要使用数据库的实现。
表关联多字段更新倒可能比较常用,在Oracle中也有同样的语法:
1 | update table1 set (col1, col2) = |
参考资料
MySQL和PostgreSQL的常用语法差异-云栖社区-阿里云
5. Rule规则系统
这个是pgsql中的一个特性。或者更准确地说,是查询重写规则系统,即把根据既定规则修改后的查询再提交给查询规划器。
实际上PostgreSQL中的视图就是通过规则系统来实现的。例如如下的查询:
1 | CREATE VIEW myview AS SELECT * FROM mytab; |
内部的规则:
1 | CREATE TABLE myview (same column list as mytab); |
pgsql中同样也有触发器。你可能会发现规则系统和触发器的作用有点相像。其实他们的作用域有重叠的部分,也有另一方无法替换的场景。
只有触发器能做的场景:约束触发器。触发器能抛出异常,而规则系统只能静默地选择处理或不处理。而只有规则系统能做更新视图。
另外触发器会对被影响的每一行触发一次,而规则系统是一次性的重写。所以在某些场景下规则系统的性能会高于触发器。
参考资料
Chapter 41. 规则系统
PostgreSQL: Documentation: 11: 41.7. Rules Versus Triggers
PostgreSQL的规则系统 | P.Linux Laboratory
6. Java开发配置
使用JPA作为数据源的时候,启动的时候会告警:
1 | Caused by: java.sql.SQLFeatureNotSupportedException: 这个 org.postgresql.jdbc.PgConnection.createClob() 方法尚未被实作。 |
这是由于Hibernate尝试验证PostgreSQL的CLOB特性,但是PostgreSQL的JDBC驱动并没有实现这个特性,所以抛出了异常。
可以增加配置,关闭这个特性的检测:
1 | spring: |
参考资料:SpringBoot连接PostgreSQL - ldp.im - 博客园
如果只使用MyBatis就不需要加这个配置了。
7. 排序规则与大小写敏感
大小写敏感分为两个不同的方面:数据库对象名的大小写敏感,以及字段内容的大小写敏感。
7.1 数据库对象名的大小写敏感
PostgreSQL在创建数据库对象(表/字段等)时,会默认将对象名改为小写。
例如会将如下的SQL
1 | SELECT FullName FROM Person |
转换为
1 | SELECT fullname FROM person |
如果一定要使用大小写敏感的对象名,则需要在创建和查询的时候都带上双引号。例如:
1 | CREATE TABLE "Person" ("FullName" VARCHAR(100), "Address" VARCHAR(100)) |
但非常不推荐这种方式。
7.2 字段内容的大小写敏感
PostgreSQL查询的时候是大小写敏感的。而且在建库时不能像MySQL那样,通过collation参数来指定数据库是否大小写敏感。
如果需要进行大小写不敏感的查询和模糊查询,可以使用如下两种方法之一:
- 等号
=或LIKE的两边的表达式加上LOWER()或UPPER() - 使用
ILIKE(应该是Insensitive Like的缩写吧)
例如:
1 | select * from person where lower(user_name) like lower('%alice%') |
或
1 | select * from person where user_name ilike '%alice%' |
LIKE和ILIKE也可以换成~~和~~*。但为了SQL的可读性和统一,还是避免使用这样的语法吧。
对于text类型的字段,可以在PostgreSQL安装citext模块后,改为citext类型。这样就可以大小写不敏感了。
7.3 字段内容的大小写敏感带来的问题
字段内容大小写敏感可能会带来三个问题:
- 排序
- 性能
- 索引
先来看排序。 因为大小写敏感,所以英文是按照ASCII排序。’a’开头的内容会被排在’B’之后。所以如果需要忽略大小写来排序,则排序字段也需要加lower:
1 | select * from person order by lower(user_name) |
性能方面,有人做过测试,使用lower+like会比ilike快17%左右。再考虑到数据库迁移过程中的兼容性,还是推荐使用lower+like。
通过UNIQUE或者PRIMARY KEY隐式产生的索引是大小写敏感的。如果使用lower的话,就不会走索引。如果对这方面有性能要求的话,可以给PostgreSQL安装上pg_trgm模块。
8. 其他MySQL与PostgreSQL比较
- PostgreSQL中天然支持emoji,不需要像MySQL中一样专门设置utf8mb4编码
- PostgreSQL和Oracle一样有物化视图
- 支持CTE语法
- 支持intersect语法
- PostgreSQL中没有单独的存储过程,是通过Function实现的
9. 其他Oracle与PostgreSQL比较
- NULL与空字符串在Oracle里是同一含义,但在pgsql中是不同的
- 同义词synonym在pg中使用
search_path来实现,例如:SET search_path TO myschema;
10. PostgreSQL独有特性
json/jsonb
这两个是PostgreSQL专有的数据类型。从用户操作的角度来说没有区别,区别主要是存储和读取的系统处理(预处理)和耗时方面有区别。json写入快,读取慢,jsonb写入慢,读取快。
有文章说jsonb的性能已经优于MongoDB的BSON。但至少有一个好处是如果需要处理json数据,在有PostgreSQL的情况下可以少引入一个数据库。
GIS
PostGIS基本成为了空间地理信息数据的存储标准。
11. 其他
如果想在本机Docker Desktop上启动pgsql,用官方的postgres:latest好像会有些问题,需要改为用alpine镜像。命令可参考:
1 | docker run --name posttest -d -p 5432:5432 -e POSTGRES_PASSWORD=postgres postgres:alpine |