我们上一章部署都是通过神奇的kubectl命令。我们这章就探寻一下,当我们拍下kubectl命令到Pod成功启动之间,Kubernetes究竟做了一些什么事情。
先上一张总的架构图,下面提到每个组件的时候可以在这张架构图上找位置,以及和其他组件间的关联关系: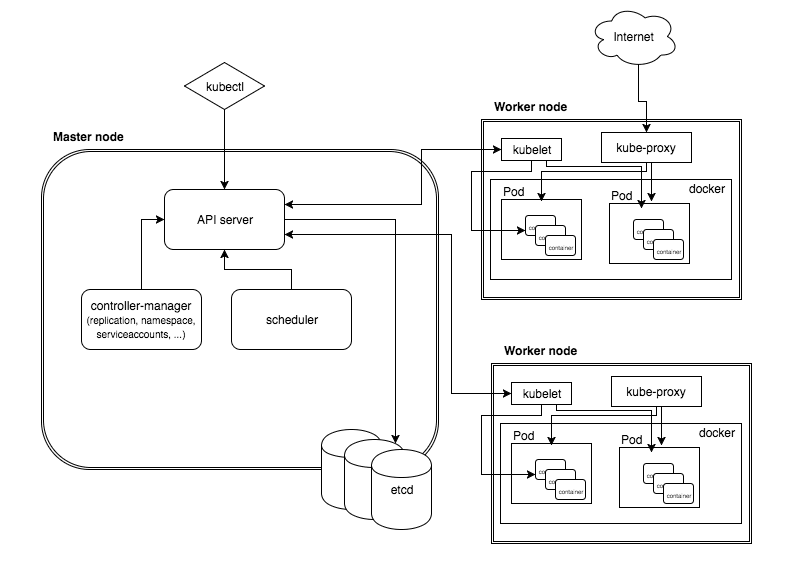
1. 全流程
1.1 Kubectl
kubectl是用于针对Kubernetes集群运行命令的命令行接口。
虽然我们是在Master节点上执行运行的kubectl,但其实kubectl也可以在本地安装,与k8s的api server远程通信交互。
kubectl在接到apply命令后,会先做一个基本的验证。如果要创建的资源不合法,或YAML格式错误,就会快速失败。
除了通过kubectl之外,也可以直接调用api,或通过dashboard UI等多种方式与api server通信。
在通信之前,kubectl需要先进行身份认证。认证信息保存在$HOME/.kube/config文件里,大致内容如下:
1 | [root@docker-4 .kube]# pwd |
config文件中的clusters.cluster.server就是要访问的api server的地址
1.2 kube-apiserver
API Server对外暴露了Kubernetes API,用于提供查询/操作/监控服务。
当接收到来自kubectl的请求后,API Server会先做三件事:
- 验证认证信息
- 确认授权,即发送请求的用户有权限进行这个操作
- 准入控制,封装了一系列额外的检查以确保操作不会产生意外或负面结果。还可以自定义插件实现自己的准入控制
1.3 etcd
etcd是一种高可用分布式存储,用于共享配置和服务发现。
之前在研究服务注册的时候还比较过它与Consul。etcd和Consul一样都是在CAP中保证CP,都是用Go语言开发的,一致性协议也都是用raft。Consul相比etcd多了多数据中心的支持。当然在k8s出现的时候还没有Consul,只有在zookeeper和etcd之间选。etcd相比zookeeper能稳定提供更大的吞吐量和延迟,而且和k8s使用的开发语言都是Go,这大概是最终选择了etcd的主要原因吧。
k8s集群将etcd当做数据库来使用,把所有的数据都存储在etcd上。当执行kubectl get命令时,结果就是从etcd中获取的。
假设kubectl执行的是创建上一篇中nginx-deployment的行为,那么最终etcd中保存的是4个对象:
- 1个Deployment对象
- 1个ReplicaSet对象
- 2个Pod对象
关于为什么还多了一个ReplicaSet对象,我们在下面说明。
1.4 Initializer初始化
在Pod还处于Pending状态,可以对Pod进行一些修改。例如给容器插入一个Sidecar容器,添加一些环境变量,挂载volume等等。Initializer初始器就是负责这个工作的。
最热门的Service Mesh–Istio项目就是通过Initializer,将Envoy容器作为Sidecar插入到每个启动的Pod中的。
1.5 控制循环
Kubernetes内部始终在运行着一个“控制循环”来实现资源的调整。
控制循环,就是控制平面的死循环。每次循环过程中,都会通过将k8s的“当前状态”和“期望状态”进行比对,来决定下一步进行什么操作。
用伪代码来描述就是:
1 | for { |
例如当刚接收到nginx-deployment的命令时,期望是要部署2个pod,实际状态是0个pod已Ready,差额是2个:
1 | [root@docker-4 deployment]# kubectl get deployment |
当部署完成后,期望状态==实际状态,部署结束:
1 | [root@docker-4 deployment]# kubectl get deployment |
1.6 DeploymentController与ReplicaSet
对于每个对象类型,由kube-controller-manager对应的controller来创建。例如Deployment就对应DeploymentController。
在一些比较早的文章里,你还能看到ReplicationController,但现在它已经不再被使用。DeploymentController是其升级版,在包含了ReplicationController所有功能的基础上还增加了回滚暂停等功能。
在说明DeploymentController之前,先提一下上一章里没有提到的一个细节:Deployment和Pod之间还隔了一层ReplicaSet。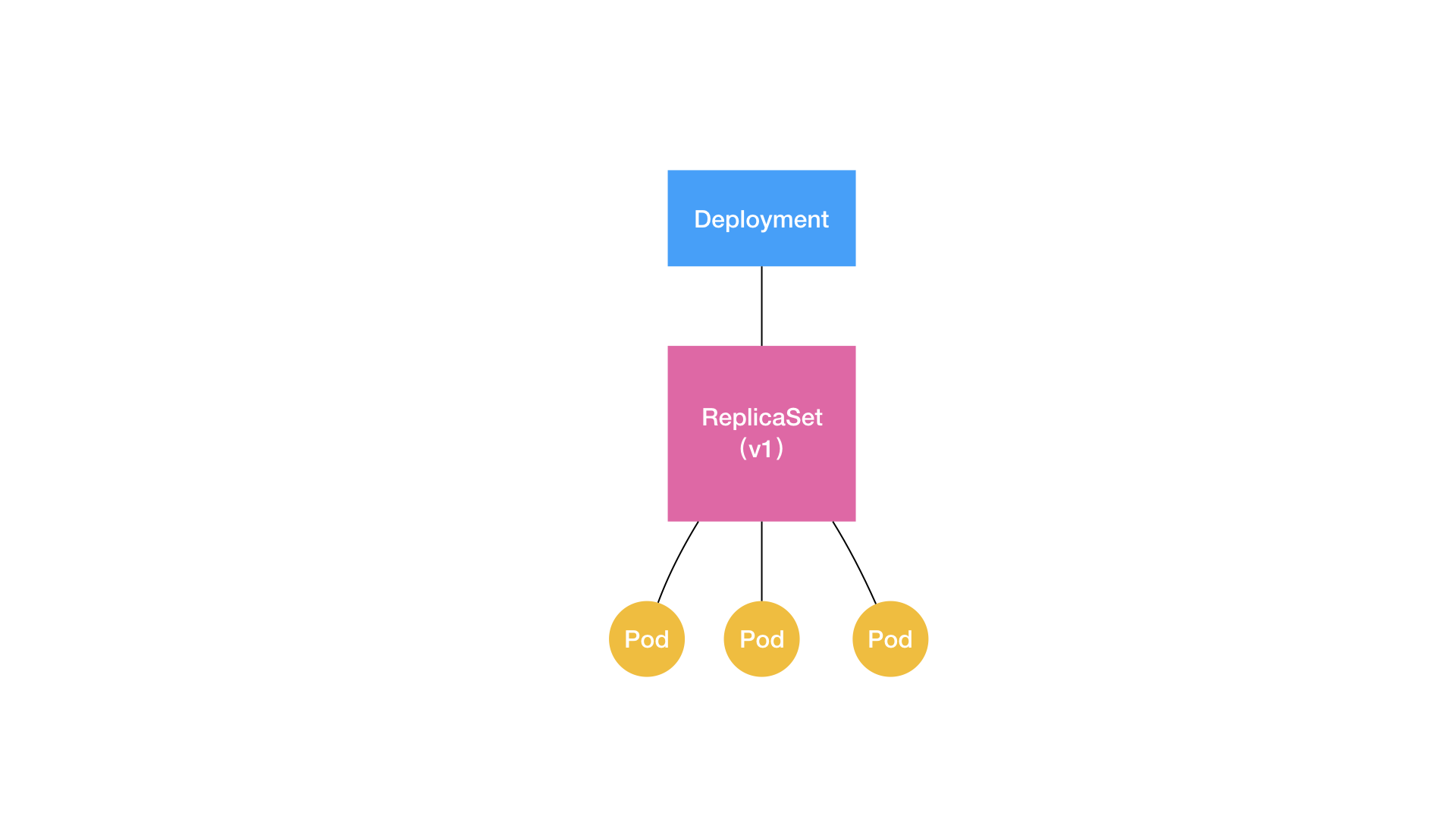
保持副本数量其实主要是靠ReplicaSet。从一个ReplicaSet的YAML可以看到,几乎和Deployment一模一样:
1 | apiVersion: apps/v1 |
但我们之所以不直接使用ReplicaSet部署,是由于ReplicaSet的功能比较简陋。当我们想实现滚动更新的时候,就需要更上一层的Deployment支援了。
DeploymentController通过一个叫Informer的模块对Deployment、ReplicaSet和Pod的变更进行监听。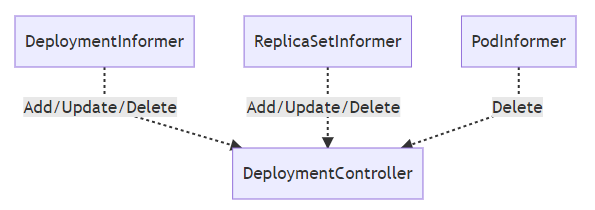
假设上述范例中poc-deployment里的应用升级了一个版本,从v1升级到了v2。控制循环会获得一个新的期望:部署两个v2的Pod。现状是有两个v1的Pod。但此时不能立即把v1的Pod停止了,不然服务就会有一段时间不可用了。在整个滚动更新的过程中,需要保证至少有两个Pod可用,无论是v1还是v2。
所以这时候Deployment会创建一个v2的ReplicaSet,包含v2的Pod。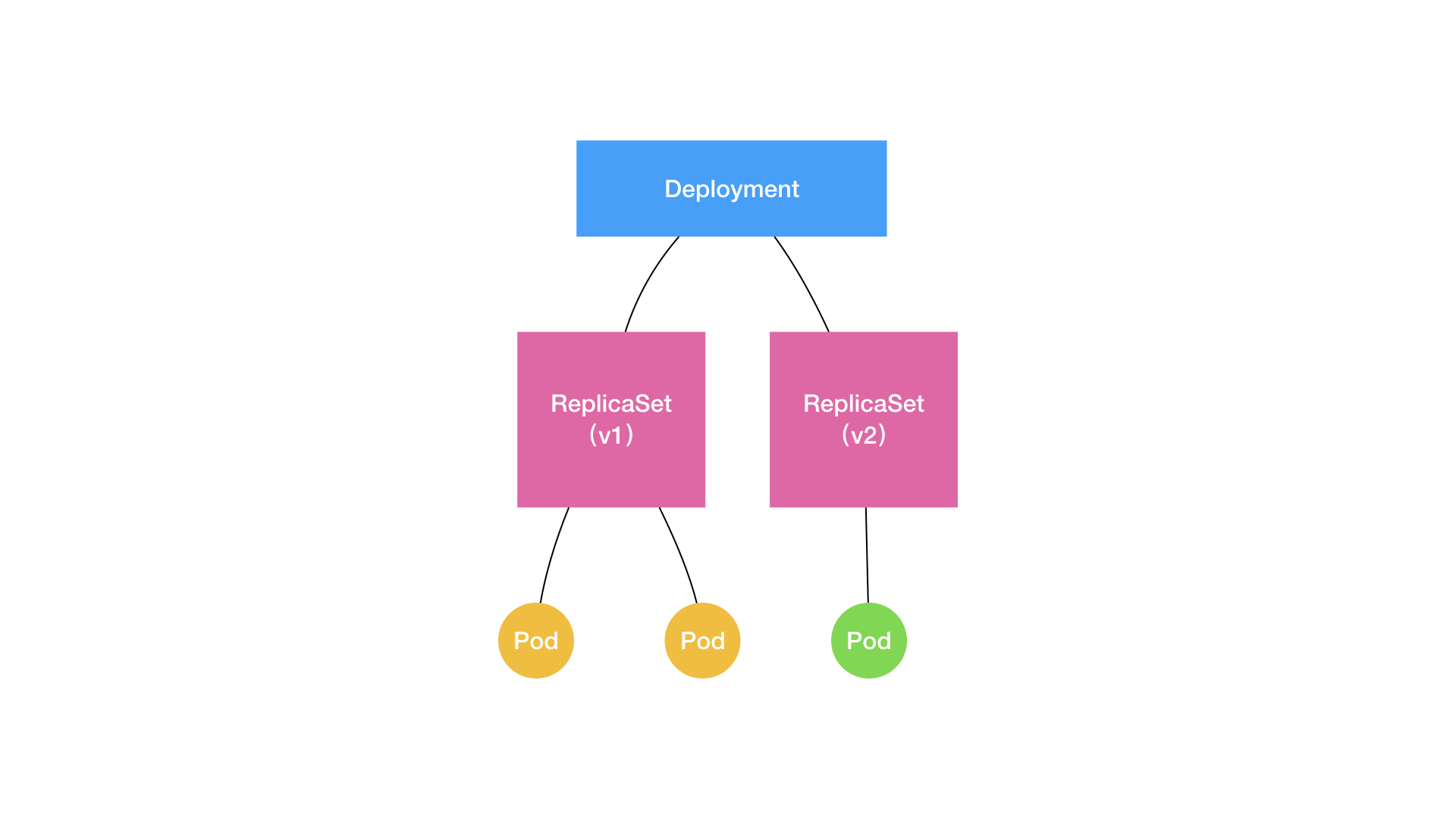
当v2的ReplicaSet中Pod的状态Ready后,v1的ReplicaSet就可以进行缩容为0个Pod了。
PS. 我们实际场景中可能会有会话黏连(session sticky)的情况存在。会话还处于活跃状态的Pod不应该被直接下线。怎么处理就是后话了。
1.7 kube-scheduler
Pod创建好之后,还没有被分派节点。kube-scheduler就是用来将待分派的Pod调度到指定Worker节点,并将节点与Pod的绑定信息也记录到etcd。
Master上的工作到此为止。
1.8 kubelet
每个Worker节点上会有一个Kubelet服务进程。kube-scheduler下发的任务就是由kubelet接收的。除此之外,它还负责:
- 挂载Pod所需要的volume
- 下载Pod的secret
- 运行容器
- 对容器生命周期进行检测
- 回报节点和Pod的状态
可以把Kubelet当成一种特殊的Controller。
至此容器正常启动,整个流程结束。
2. 声明式API
kubectl apply和docker run看上去是两句很类似的命令,但表现出来的理念截然不同。
docker run是命令式的。你发出命令,服务器接收,并按照命令创建出容器。
但Kuberentes的API是所谓的“声明式”,即你向Kubernetes提交一个定义好的API对象,声明自己想要达到的目标状态。当Kubernetes接收到这个目标状态后,自己内部协调各种组件,达成并保持这个状态。
声明式对于分布式系统有着重大的意义。
- 首先是能实现自动化调整。分布式系统的每个组件都可能会随时发生故障。假设一个节点在部署某个Pod的过程中突然挂掉了,如果采用的是命令式API,就需要人工干预:“我换个节点再重新拍命令。等恢复那个节点后再进行之前操作的回滚”。但对于使用了声明式API的Kubernetes,会在每个控制循环的开始检查:“之前部署Pod的任务还没完成,和kubelet联系一下,问问看Node进展如何了?怎么联系不上Node?换个Node部署吧。”在挂掉的Node恢复后,它会自动调用API Server获取当前状态并进行分析:“之前要我部署的Pod已经在其他Node上部署好了?如果我继续部署的话,Pod数量就比目标多了。那么我把自己进行到一半的操作回滚吧。”整个过程完全无需外界干预。
- 其次,对于命令式API,每个命令都是独占且阻塞的。只有先等前一个命令执行完之后才能执行下一个命令,不然就有出现冲突的可能。而声明式API使得多个写操作都能并行执行,使得处理效率大大提升。
- 此外,声明式API还支持操作的合并。你可以设置一个YAML为基础YAML,在用户提交YAML后会和基础YAML合并,然后再提交给API Server。我感觉这有点像Java里的自定义拦截器。知名的Istio项目是主要实现原理也就是靠这种方式注入Envoy。
3. 参考资料
本篇主要参考了jamiehannaford/what-happens-when-k8s: What happens when I type kubectl run?
翻译版
对k8s如何使用etcd的简要介绍
How Does Kubernetes Use etcd?
Deployment原理主要是参考这篇
详解 Kubernetes Deployment 的实现原理
关于Informer机制的更详细介绍
Kubernetes Informer 详解_Kubernetes中文社区
这篇是Kubernetes的开发者介绍的Kubernetes设计原则,值得完整读一下
Kubernetes 设计与开发原则 - 杨传胜的博客|Cloud Native|yangcs.net
原文是这篇:
Kubernetes Design and Development Explained - The New Stack